Chapter 41 Multiple Regression with the hydrate data
41.1 Another Scatterplot Matrix for the hydrate data
Along the diagonals of the scatterplot matrix, we have histograms of each of the variables. In the first row of the matrix, we have scatterplots of Recovery (on the y-axis) against each of the predictor variables in turn. We see a positive relationship with Dose, and a negative relationship with both Age, and then Weight. All possible scatterplots are shown, including plots that look at the association between the predictor variables.
pairs (~ recov.score + dose + age + weight, data=hydrate,
main="Hydrate Scatterplot and Correlation Matrix",
upper.panel = panel.smooth,
diag.panel = panel.hist,
lower.panel = panel.cor)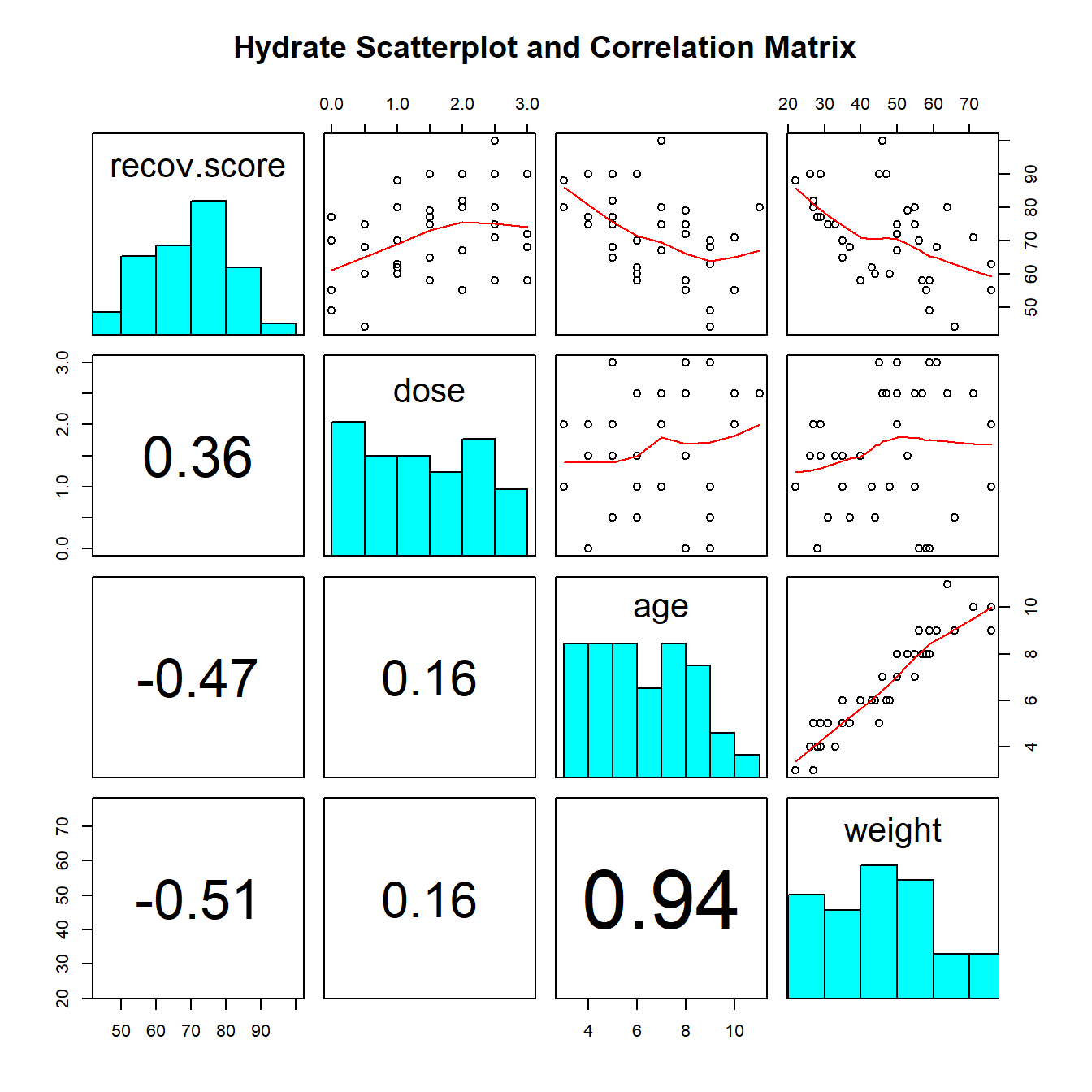
We see the positive correlation between Recovery and Dose (+.36) and the negative correlations between Recovery and Age (-.47) and Recovery and Weight (-.51). We can also see a very strong positive correlation between Weight and Age (+.94), which implies that it may be very difficult to separate out the effect of Weight from the effect of Age on our response.
41.2 A Multiple Regression for recov.score
Our first multiple linear regression model will predict recov.score using three predictors: dose, age and weight.
Call:
lm(formula = recov.score ~ dose + age + weight, data = hydrate)
Residuals:
Min 1Q Median 3Q Max
-16.68 -6.49 -2.20 7.67 22.13
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 85.476 5.965 14.33 1.8e-15 ***
dose 6.170 1.791 3.45 0.0016 **
age 0.277 2.285 0.12 0.9043
weight -0.543 0.324 -1.68 0.1032
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.92 on 32 degrees of freedom
Multiple R-squared: 0.458, Adjusted R-squared: 0.408
F-statistic: 9.03 on 3 and 32 DF, p-value: 0.00017741.2.1 Model Specification
Call:
lm(formula = recov.score ~ dose + age + weight)The output begins by presenting the R function call. Here, we have a linear model, with recov.score being predicted using dose, age and weight, all from the hydrate data.
41.2.2 Model Residuals
Residuals:
Min 1Q Median 3Q Max
-16.682 -6.492 -2.204 7.667 22.128 Next, we summarize the residuals, where Residual = Actual Value - Predicted Value.
- This gives us a sense of how incorrect our predictions are for the
hydrateobservations.- The residuals will center near 0 (least squares is designed so the mean will always be zero, here the median prediction is 2.2 points too high)
- Here, we predicted a
recov.scorethat was 16.68 points too high for one patient, and another of our predictedrecov.scorevalues was 22.13 points too low. - The middle half of our predictions were between 6.5 points too high (so the residual = observed - predicted is -6.5) and 7.7 points too low.
41.2.3 Model Coefficients
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 85.4764 5.9653 14.329 1.79e-15 ***
dose 6.1697 1.7908 3.445 0.00161 **
age 0.2770 2.2847 0.121 0.90428
weight -0.5428 0.3236 -1.677 0.10325
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The first column of this table gives the estimated coefficients for our model (including the intercept, and slopes for each of our three predictors). Our least squares equation is recov.score = 85.48 + 6.17 dose + 0.28 age - 0.54 weight.
41.2.4 Interpreting the t tests (last predictor in)
Next to each coefficient is its estimated standard error, followed by the coefficient’s t value (the coefficient value divided by the standard error), and the associated two-tailed p value. The p value addresses H0: This coefficient’s \(\beta\) value = 0, as last predictor into the model.
- The t test of the intercept is rarely of interest, because
- we rarely care about the situation that the intercept predicts; where all of the predictor variables are equal to zero, and
- we usually are going to keep the intercept in the model regardless of its statistical significance.
The t test for dose tests the hypothesis that the slope of dose should be zero, as last predictor in.
- If the slope of
dosewas in fact zero, that would mean that knowing thedoseinformation would be of no additional value in predicting the outcome after you have accounted forageandweightin your model. - Last predictor in
- This last predictor in business means that the test is comparing a model with
dose,ageandweightto a model withageandweightalone, to see if the incremental benefit of adding dose provides statistically significant additional predictive value forrecov.score. - The t test tells us if
doseis a useful addition to a model that already contains the other two variables. - The p value = .0016, so, at any reasonable \(\alpha\) level, the
dosereceived is a significant part of the predictive model, even after accounting forageandweight.
- This last predictor in business means that the test is comparing a model with
41.2.4.1 The t test of age
The t test of age tests H0: age has no predictive value for recov.score as last predictor in.
- Here p = .9043, which indicates that
agedoesn’t add statistically significant predictive value to the model once we have adjusted fordoseandweight. - This does not mean that
age, by itself, has no linear relationship withrecov.score, but it does mean that in this model, it doesn’t help to addageonce we already havedoseandweight. - This shouldn’t be surprising, given the strong correlation between
ageandweightshown in the scatterplot matrix.
41.2.4.2 The t test of weight
The t test of weight tests the null hypothesis that weight has no predictive value for recov.score as last predictor in.
- Here p = .1032, which is better than we saw in the
agevariable, but still indicates thatweightadds no significant predictive value to the model forrecov.scoreif we already havedoseandage.
41.2.5 The Effect of Collinearity
The situation we see here with age and weight, where two predictors are highly correlated with one another, making it hard to see significant predictive value for either one of them after the other is already in the model is referred to as collinearity.
- Our usual approach to dealing with this collinearity will be to consider dropping one predictor from our model, and refit.
- Dropping either predictor will likely have a fairly small impact on the fit quality of our model, but if we drop both, we may do a lot of damage.
41.2.6 Confidence Intervals for the Slopes in a Multiple Regression Model
Here are the confidence intervals for the coefficients of our multiple regression model.
2.5 % 97.5 %
(Intercept) 73.33 97.627
dose 2.52 9.817
age -4.38 4.931
weight -1.20 0.116We conclude, for instance, with 95% confidence, that that true slope of dose is between 2.52 and 9.82 points on the recovery score scale.
This is pretty different from the confidence interval we found for the slope of dose in a simple regression on dose alone that we saw previously, and repeat below.
2.5 % 97.5 %
(Intercept) 55.827 72.0
dose 0.466 9.3In both cases, the reasonable range of values for the slope of dose appears to be positive, but the range of values is much tighter in the multiple regression.
41.2.7 Model Summaries
Residual standard error: 9.923 on 32 degrees of freedom
Multiple R-squared: 0.4584, Adjusted R-squared: 0.4077
F-statistic: 9.03 on 3 and 32 DF, p-value: 0.0001769The residual standard error estimates the standard deviation of our model’s errors to be 9.923.
- We’d expect roughly 95% of our residuals to fall between -2(9.923) and +2(9.923), or roughly -20 to +20.
- We’d expect to see virtually no residuals outside the range of \(\pm\) 3(9.923) or roughly -30 to +30.
The coefficient of determination, R2, is estimated to be 0.4584
- We accounted for just under 46% of the variation in
recov.scoreusingdose,ageandweight.
R2 will always suggest that we make our models as big as possible, often including variables of dubious predictive value.
- An important thing to realize is that if you add a variable to a model, R2 cannot decrease.
- Similarly, removing a variable from a model, no matter how unrelated to the outcome, cannot increase the R2 value.
- Thus, using R2 as the be-all and end-all of model fit for a regression model goes against the general notion that we would like to have parsimonious models; that is to say, we favor simple models when possible.
The overall ANOVA F test is presented last.
- The test gives an F-statistic of 9.03 on 3 and 32 degrees of freedom, yielding a p value of .00018.
- We can conclude (at any reasonable \(\alpha\) level) that there is statistically significant predictive value somewhere in this model.
- The F test for a multiple regression is a very low standard; specifying only that we have conclusive evidence that some part of the model predicts the outcome to a degree beyond that easily attributed to chance alone.
- We return to the individual t tests to assess significance after adjusting for the other predictors.
- Concluding that the F test is significant means that the multiple R2 accounted for by the model is also statistically significant.
41.2.7.1 Verifying the R2 Calculations
The formula for R2 is simply the sum of squares accounted for by the regression model divided by the total sum of squares.
- This is the same as 1 minus [residual sum of squares divided by total sum of squares].
- We can verify the calculation with the complete ANOVA table for this model
Analysis of Variance Table
Response: recov.score
Df Sum Sq Mean Sq F value Pr(>F)
dose 1 752 752 7.64 0.00940 **
weight 1 1914 1914 19.44 0.00011 ***
age 1 1 1 0.01 0.90428
Residuals 32 3151 98
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1So \(R^2 = 1 - \frac{SS(Residual)}{SS(Total)} = 1 - \frac{3151.22}{752.15 + 1914.07 + 1.45 + 3151.22} = 1 - \frac{3151.22}{5818.89}\) = 1 - 0.5416 = .4584
If we are fitting a model to n data points, and we have k coefficients (slopes + intercept) in our model, then the model’s adjusted R2 is \(R^2_{adj} = 1 - \frac{(1-R^2)(n - 1)}{n - k}\).
In the hydrate data, we have n = 36 data points, and k = 4 coefficients (3 slopes, plus the intercept), so \(R^2_{adj} = 1 - \frac{(1-.4584)(36 - 1)}{36 - 4}\) = .4077
- Again, the adjusted R2 is not interpreted as a percentage of anything, and can in fact be negative.
- \(R^2_{adj}\) will always be less than the original R2 so long as there is at least one predictor besides the intercept term, so that k > 1 in the equation above.
41.3 ANOVA for Sequential Comparison of Models
Outside of the main summary, we can also run a sequence of comparisons of the impact of various predictors in our model with the anova function.
Analysis of Variance Table
Response: recov.score
Df Sum Sq Mean Sq F value Pr(>F)
dose 1 752 752 7.64 0.00940 **
age 1 1639 1639 16.64 0.00028 ***
weight 1 277 277 2.81 0.10325
Residuals 32 3151 98
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1This ANOVA table is very different from the one we saw in our simple regression model. The various p values shown here indicate the significance of predictors taken in turn, specifically…
- The p value for H0:
dosehas significant predictive value by itself is 0.009 - The p value for H0:
ageadds significant predictive value once you already havedosein the model is 0.0003 - The p value for H0:
weightadds significant predictive value once you already havedoseandagein the model (i.e. as last predictor in) is 0.1032
Note that this last p value is the same as the t test for weight we have already seen in the main summary of the model.
If we change the order of the predictors entering the model, the main summary of our linear model will not change, but these ANOVA results will change.
Call:
lm(formula = recov.score ~ dose + weight + age, data = hydrate)
Residuals:
Min 1Q Median 3Q Max
-16.68 -6.49 -2.20 7.67 22.13
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 85.476 5.965 14.33 1.8e-15 ***
dose 6.170 1.791 3.45 0.0016 **
weight -0.543 0.324 -1.68 0.1032
age 0.277 2.285 0.12 0.9043
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.92 on 32 degrees of freedom
Multiple R-squared: 0.458, Adjusted R-squared: 0.408
F-statistic: 9.03 on 3 and 32 DF, p-value: 0.000177Analysis of Variance Table
Response: recov.score
Df Sum Sq Mean Sq F value Pr(>F)
dose 1 752 752 7.64 0.00940 **
weight 1 1914 1914 19.44 0.00011 ***
age 1 1 1 0.01 0.90428
Residuals 32 3151 98
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1- Does
ageadd significant predictive value to the model includingdoseandweight?- No, because the p value for
ageis 0.904 once we have previously accounted fordoseandweight.
- No, because the p value for
- Does
weightadd significant predictive value to the model that includesdoseonly?- Yes, because the p value for
weightis 0.00011 once we have accounted fordose.
- Yes, because the p value for
41.3.1 Building The ANOVA Table for The Model
Sometimes, we want an ANOVA table for the Regression as a whole, to compare directly to the Residuals. We can build this by adding up the sums of squares and degrees of freedom from the individual predictors, then calculating the Mean Square and F ratio for the Regression.
- The degrees of freedom are easy. We have three predictors (slopes), each accounting for one DF, and we have 32 DF applied to the residuals, so total DF = n - 1 = 35
| ANOVA Table | DF | SS | MS | F | p value |
|---|---|---|---|---|---|
| Regression | 3 | ? | ? | ? | ? |
| Residuals | 32 | 3151.22 | 98.48 | ||
| Total | 35 | ? |
- To obtain the sum of squares due to the regression model, we just add the sums of squares for the individual predictors, so SS(Regression) = 752.15 + 1914.07 + 1.45 = 2667.67
- The total sum of squares is then the sum of SS(Regression) and SS(Residuals): here, 2667.67 + 3151.22 = 5818.89
- Now, we recall that the Mean Square for any row in this table is just the Sum of Squares divided by the degrees of freedom, so that MS(Regression) = 2667.67 / 3 = 889.22
| ANOVA Table | DF | SS | MS | F | p value |
|---|---|---|---|---|---|
| Regression | 3 | 2667.67 | 889.22 | ? | ? |
| Residuals | 32 | 3151.22 | 98.48 | ||
| Total | 35 | 5818.89 |
- The F ratio and p value can be obtained from the original summary of the model.
| ANOVA Table | DF | SS | MS | F | p value |
|---|---|---|---|---|---|
| Regression | 3 | 2667.67 | 889.22 | 9.03 | 0.00018 |
| Residuals | 32 | 3151.22 | 98.48 | ||
| Total | 35 | 5818.89 |
We can use this to verify that the R2 for the model is also equal to SS(Regression) / SS(Total)
\(R^2 = \frac{SS(Regression)}{SS(Total)} = \frac{2667.67}{5818.89}\) = 0.4584
41.4 Standardizing the Coefficients of a Model
Which of the three predictors: dose, age and weight, in our model for recov.score, has the largest effect?
Sometimes, we want to express the coefficients of the regression in a standardized way, to compare the impact of each predictor within the model on a fairer scale. A common trick is to “standardize” each input variable (predictor) by subtracting its mean and dividing by its standard deviation. Each coefficient in this semi-standardized model is the expected difference in the outcome, comparing subjects that differ by one standard deviation in one variable with all other variables fixed at their average. R can do this rescaling quite efficiently, with the use of the scale function.
41.4.1 A Semi-Standardized Model for the hydrate data
Call:
lm(formula = recov.score ~ scale(dose) + scale(weight) + scale(age),
data = hydrate)
Residuals:
Min 1Q Median 3Q Max
-16.68 -6.49 -2.20 7.67 22.13
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 71.556 1.654 43.26 <2e-16 ***
scale(dose) 5.860 1.701 3.45 0.0016 **
scale(weight) -8.040 4.794 -1.68 0.1032
scale(age) 0.581 4.793 0.12 0.9043
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.92 on 32 degrees of freedom
Multiple R-squared: 0.458, Adjusted R-squared: 0.408
F-statistic: 9.03 on 3 and 32 DF, p-value: 0.000177The only things that change here are the estimates and standard errors of the coefficients: every other bit of the output is unchanged from our original summary.
- Each of the scaled covariates has mean zero and standard deviation one.
scale(dose), for instance, is obtained by subtracting the mean from the originaldosevariable (so the result is centered at zero) and dividing that by the standard deviation (so thatscale(dose)has mean 0 and standard deviation 1.)- We interpret the coefficient of
scale(dose)= 5.86 as the change in our outcome (recov.score) that we anticipate when the dose increases by one standard deviation from its mean, while all of the other inputs (weightandage, specifically) remain at their means.
This allows us to compare the effects on recov.score due to dose, to weight and to age in terms of a change of one standard deviation in each, while holding the others constant.
- Which of the inputs appears to have the biggest impact on recovery score in this sense?
41.4.1.1 Interpreting the Intercept in a Model with Semi-Standardized Coefficients
The semi-standardized model has an interesting intercept term. The intercept is equal to the mean of our outcome (recov.score) across the full set of subjects.
- When
scale(dose),scale(weight)andscale(age)are all zero, this means thatdose,weightandageare at their means. - So the intercept tells you the value of
recov.scorethat we would predict when all of the scaled predictors are zero, e.g., when all of the original inputs to the model (dose,weightandage) are at their average values.
41.5 Comparing Fits of Several Possible Models for Recovery Score
Below, I summarize the results for five possible models for recov.score. What can we conclude? By this set of results, which of the models looks best?
| Model | Fitted Equation | R2 | \(R^2_{adj}\) | RSE | F test p |
|---|---|---|---|---|---|
| [Int] | 71.6 | - | - | 12.89 | - |
| D | 63.9 + 4.88 dose |
.1293 | .1037 | 12.21 | 0.0313 |
| DA | 84.1 + 6.07 dose - 3.31 age |
.4108 | .3751 | 10.19 | 0.0002 |
| DW | 85.6 + 6.18 dose - 0.51 weight |
.4582 | .4254 | 9.77 | 4.1e-05 |
| DAW | 85.5 + 6.17 dose + 0.28 age - 0.54 weight |
.4584 | .4077 | 9.92 | 0.0002 |
It appears as though the DW model is almost as good as the DAW model using the multiple R2 as a criterion, and is the best of these five models using any of the other criteria.
The five summaries I used to obtain this table were obtained with the following code (not evaluated here):
summary(lm(recov.score ~ 1))
summary(lm(recov.score ~ dose))
summary(lm(recov.score ~ dose + age))
summary(lm(recov.score ~ dose + weight))
summary(lm(recov.score ~ dose + age + weight))41.6 Comparing Model Fit: The AIC, or Akaike Information Criterion
Another summary we’ll use to evaluate a series of potential regression models for the same outcome is the Akaike Information Criterion or AIC. Smaller values indicate better models, by this criterion, which is just a measure of relative quality.
| Model | Intercept only | D | DA | DW | DAW |
|---|---|---|---|---|---|
| AIC | 289.24 | 286.25 | 274.19 | 271.17 | 273.16 |
By the AIC, DW looks best out of these five models.
Note: R uses the AIC function applied to a model to derive these results. For example,
[1] 289[1] 27341.7 Comparing Model Fit with the BIC, or Bayesian Information Criterion
Another summary we’ll use to evaluate potential regression models for the same outcome is the Bayesian Information Criterion or BIC. Like the AIC, smaller values indicate better models, by this criterion, which is also a measure of relative quality.
| Model | Intercept only | D | DA | DW | DAW |
|---|---|---|---|---|---|
| BIC | 292.4 | 291.0 | 280.5 | 277.5 | 281.1 |
By the BIC, as well, DW looks best out of these five models.
To obtain the results, just apply BIC instead of AIC to the model.
[1] 27841.8 Making Predictions for New Data: Prediction vs. Confidence Intervals
The predict function, like the fitted function, when applied to a linear model, can produce the fitted values predicted by the model. Yet there is more we can do with predict.
Suppose we want to use the model to predict our outcome (recovery score, or recov.score) on the basis of the three predictors (dose, age and weight.) Building an interval forecast around a fitted value requires us to decide whether we are:
- predicting the
recov.scorefor one particular child with the specified characteristics (in which case we use something called a prediction interval) or - predicting the mean
recov.scoreacross all children that have the specifieddose,ageandweightcharacteristics (in which case we use a confidence interval).
The prediction interval will always be wider than the related confidence interval.
41.8.1 Making a Prediction using the hydrate data
Now, suppose that we wish to predict a recov.score associated with dose = 2, age = 7 and weight = 50. The approach I would use follows…
modela <- lm(recov.score ~ dose + age + weight, data = hydrate)
newdata <- data.frame(dose = 2, age = 7, weight = 50)
predict(modela, newdata, interval="prediction", level=0.95) fit lwr upr
1 72.6 52.1 93.2 fit lwr upr
1 72.6 68.9 76.4So, our conclusions are:
- If we have one particular child with
dose= 2,age= 7 andweight= 50, we have 95% confidence that therecov.scorefor this child will be between 52.1 and 93.2. - If we have a large group of children with
dose= 2,age= 7 andweight= 50, we have 95% confidence that the averagerecov.scorefor these children will be between 68.9 and 76.4.
41.8.2 A New Prediction?
Suppose that now you wanted to make a prediction for a recov.score with dose = 1, age = 4 and weight = 60. Why would this be a meaningfully worse idea than the prediction we just made, and how does the plot below tell us this?
ggplot(hydrate, aes(x = age, y = weight)) +
geom_point() +
labs(title = "Weight vs. Age in the hydrate data")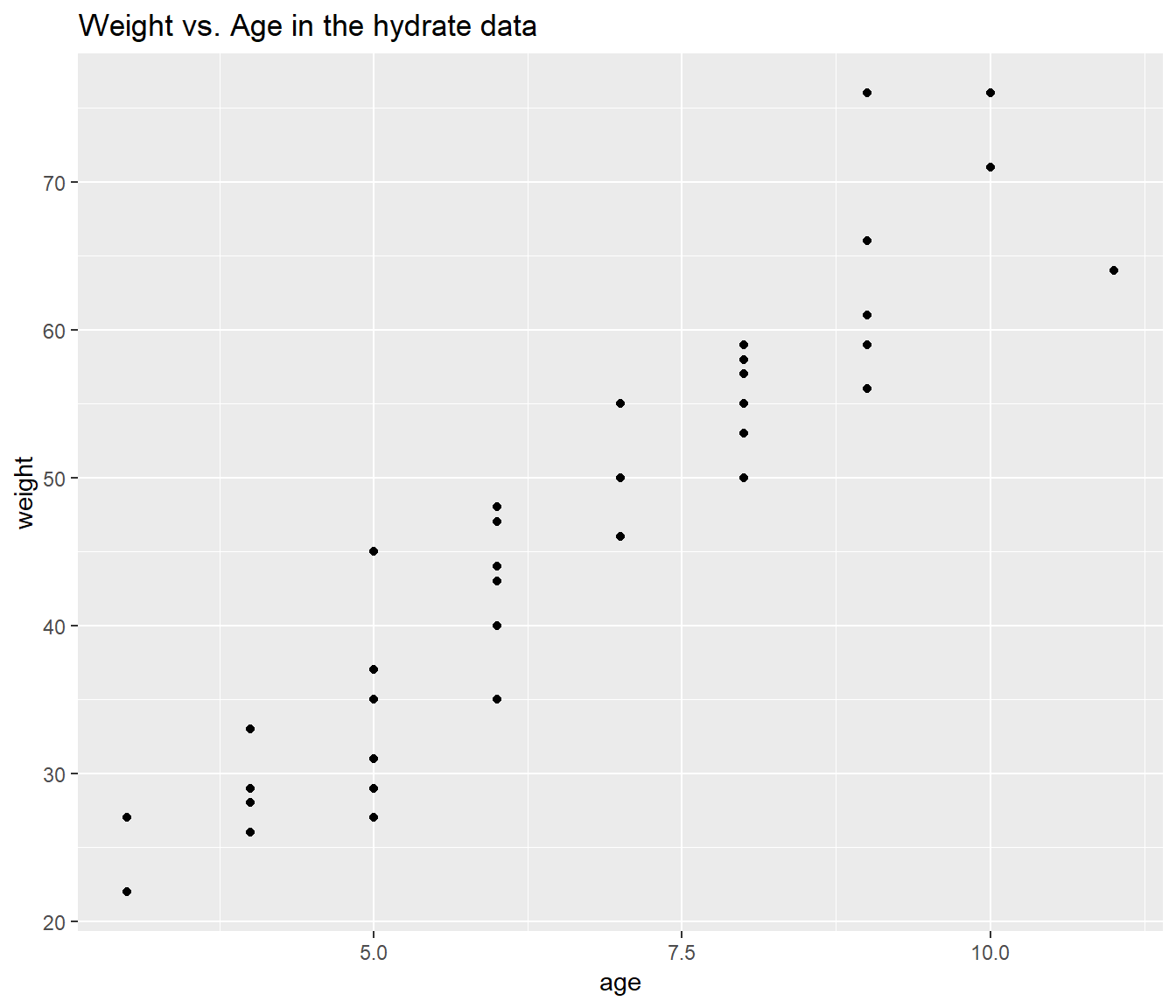
41.9 Interpreting the Regression Model: Two Key Questions
Suppose we land, finally, on the DW model…
Call:
lm(formula = recov.score ~ dose + weight, data = hydrate)
Residuals:
Min 1Q Median 3Q Max
-16.61 -6.49 -2.12 7.60 22.25
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 85.594 5.797 14.77 4.3e-16 ***
dose 6.175 1.763 3.50 0.0013 **
weight -0.506 0.113 -4.48 8.6e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.77 on 33 degrees of freedom
Multiple R-squared: 0.458, Adjusted R-squared: 0.425
F-statistic: 14 on 2 and 33 DF, p-value: 4.06e-05Suppose we decide that this model is a reasonable choice, based on adherence to regression assumptions (as we’ll discuss shortly), and quality of fit as measured both by R2 measures, the various hypothesis tests, and the information criteria (AIC and BIC).
Question 1. Can we summarize the model and how well it fits the data in a reasonable English sentence or two?
- Together, dose and weight account for just under 46% of the variation in recovery scores, and this is highly statistically significant (p < 0.001). Higher recovery scores are associated with higher doses and with lower weights among the 36 children assessed in this study.
Question 2. How might we interpret the coefficient of dose for someone who was smart but not a student of statistics?
- If we have two kids who are the same weight, then if kid A receives a dose that is 1 mEq/L larger than kid B, we’d expect kid A’s recovery score to be a little over 6 points better than the score for kid B.