Chapter 12 Studying Crab Claws (crabs)
For our next example, we’ll consider a study from zoology, specifically carcinology - the study of crustaceans. My source for these data is Chapter 7 in Ramsey and Schafer (2002) which drew the data from a figure in Yamada and Boulding (1998).
The available data are the mean closing forces (in Newtons) and the propodus heights (mm) of the claws on 38 crabs that came from three different species. The propodus is the segment of the crab’s clawed leg with an immovable finger and palm.

Figure 12.1: Source: http://txmarspecies.tamug.edu/crustglossary.cfm
This was part of a study of the effects that predatory intertidal crab species have on populations of snails. The three crab species under study are:
- 14 Hemigraspus nudus, also called the purple shore crab (14 crabs)
- 12 Lophopanopeus bellus, also called the black-clawed pebble crab, and
- 12 Cancer productus, one of several species of red rock crabs (12)
# A tibble: 38 x 4
crab species force height
<int> <fct> <dbl> <dbl>
1 1 Hemigraspus nudus 4 8
2 2 Lophopanopeus bellus 15.1 7.9
3 3 Cancer productus 5 6.7
4 4 Lophopanopeus bellus 2.9 6.6
5 5 Hemigraspus nudus 3.2 5
6 6 Hemigraspus nudus 9.5 7.9
7 7 Cancer productus 22.5 9.4
8 8 Hemigraspus nudus 7.4 8.3
9 9 Cancer productus 14.6 11.2
10 10 Lophopanopeus bellus 8.7 8.6
# ... with 28 more rowsHere’s a quick summary of the data. Take care to note the useless results for the first two variables. At least the function flags with a * those variables it thinks are non-numeric.
vars n mean sd median trimmed mad min max range skew
crab 1 38 19.50 11.11 19.50 19.50 14.08 1 38.0 37.0 0.00
species* 2 38 2.00 0.81 2.00 2.00 1.48 1 3.0 2.0 0.00
force 3 38 12.13 8.98 8.70 11.53 9.04 2 29.4 27.4 0.47
height 4 38 8.81 2.23 8.25 8.78 2.52 5 13.1 8.1 0.19
kurtosis se
crab -1.30 1.80
species* -1.50 0.13
force -1.25 1.46
height -1.14 0.36Actually, we’re more interested in these results after grouping by species.
# A tibble: 3 x 4
species n `median(force)` `median(height)`
<fct> <int> <dbl> <dbl>
1 Cancer productus 12 19.7 11.0
2 Hemigraspus nudus 14 3.7 7.9
3 Lophopanopeus bellus 12 14.8 8.1512.1 Association of Size and Force
Suppose we want to describe force on the basis of height, across all 38 crabs. We’ll add titles and identify the three species of crab, using shape and color.
ggplot(crabs, aes(x = height, y = force, color = species, shape = species)) +
geom_point(size = 3) +
labs(title = "Crab Claw Force by Size",
x = "Claw's propodus height (mm)", y = "Mean closing force (N)") +
theme_bw()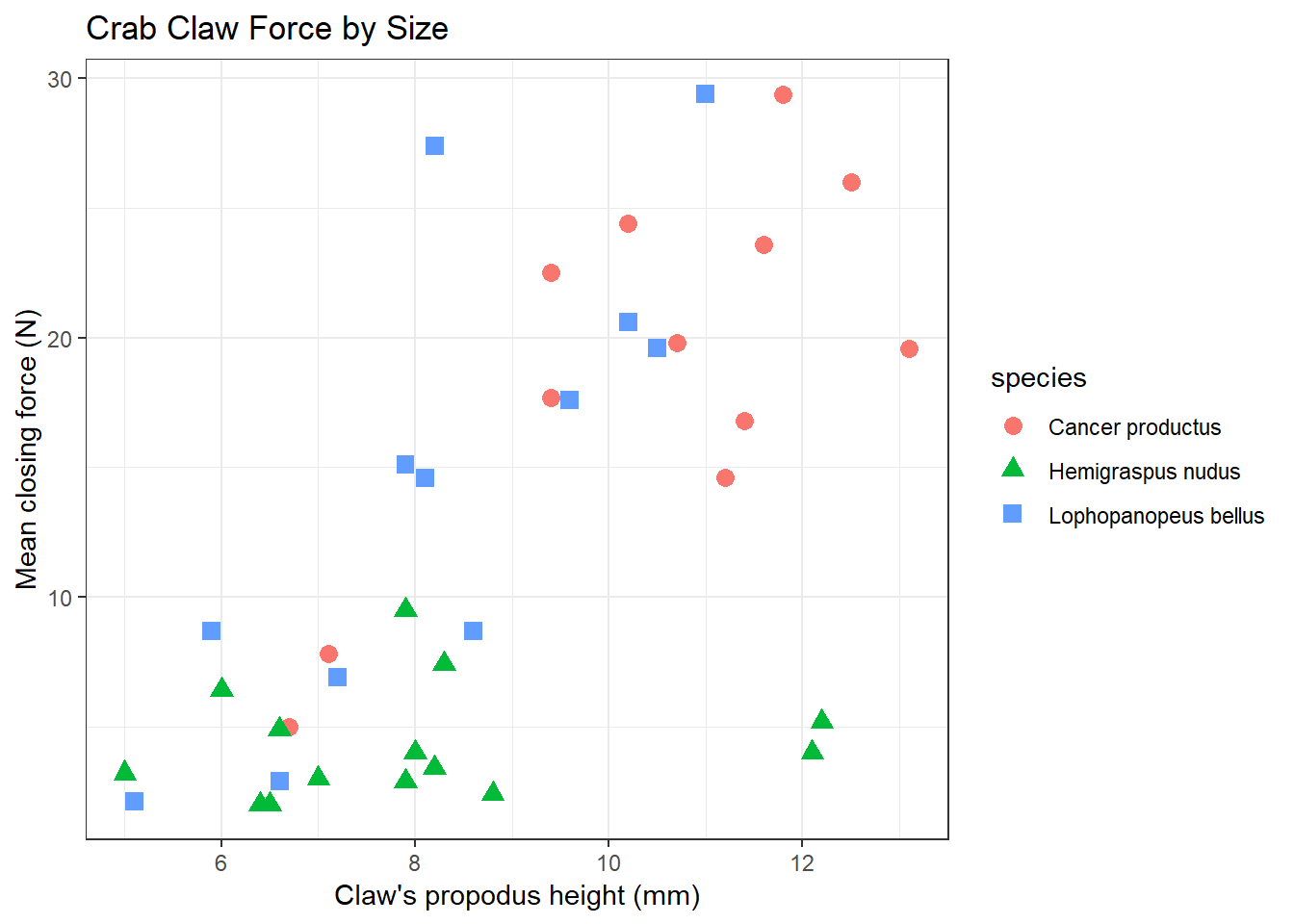
A faceted plot for each species really highlights the difference in force between the Hemigraspus nudus and the other two species of crab.
ggplot(crabs, aes(x = height, y = force, color = species)) +
geom_point(size = 3) +
facet_wrap(~ species) +
guides(color = FALSE) +
labs(title = "Crab Claw Force by Size",
x = "Claw's propodus height (mm)", y = "Mean closing force (N)") +
theme_bw()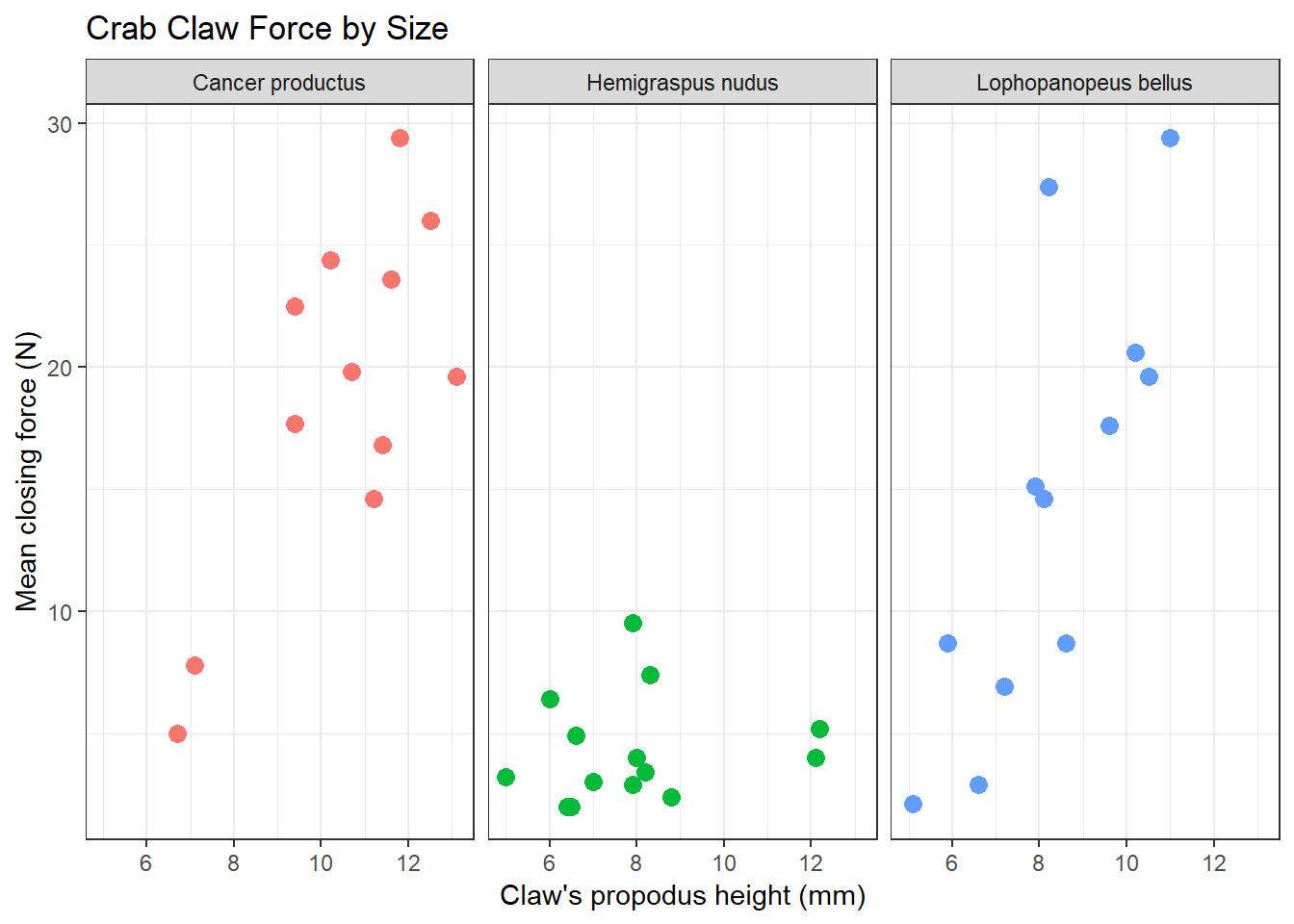
12.2 The loess smooth
We can obtain a smoothed curve (using several different approaches) to summarize the pattern presented by the data in any scatterplot. For instance, we might build such a plot for the complete set of 38 crabs, adding in a non-linear smooth function (called a loess smooth.)
ggplot(crabs, aes(x = height, y = force)) +
geom_point() +
geom_smooth(method = "loess", se = FALSE) +
labs(title = "Crab Claw Force by Size",
x = "Claw's propodus height (mm)", y = "Mean closing force (N)")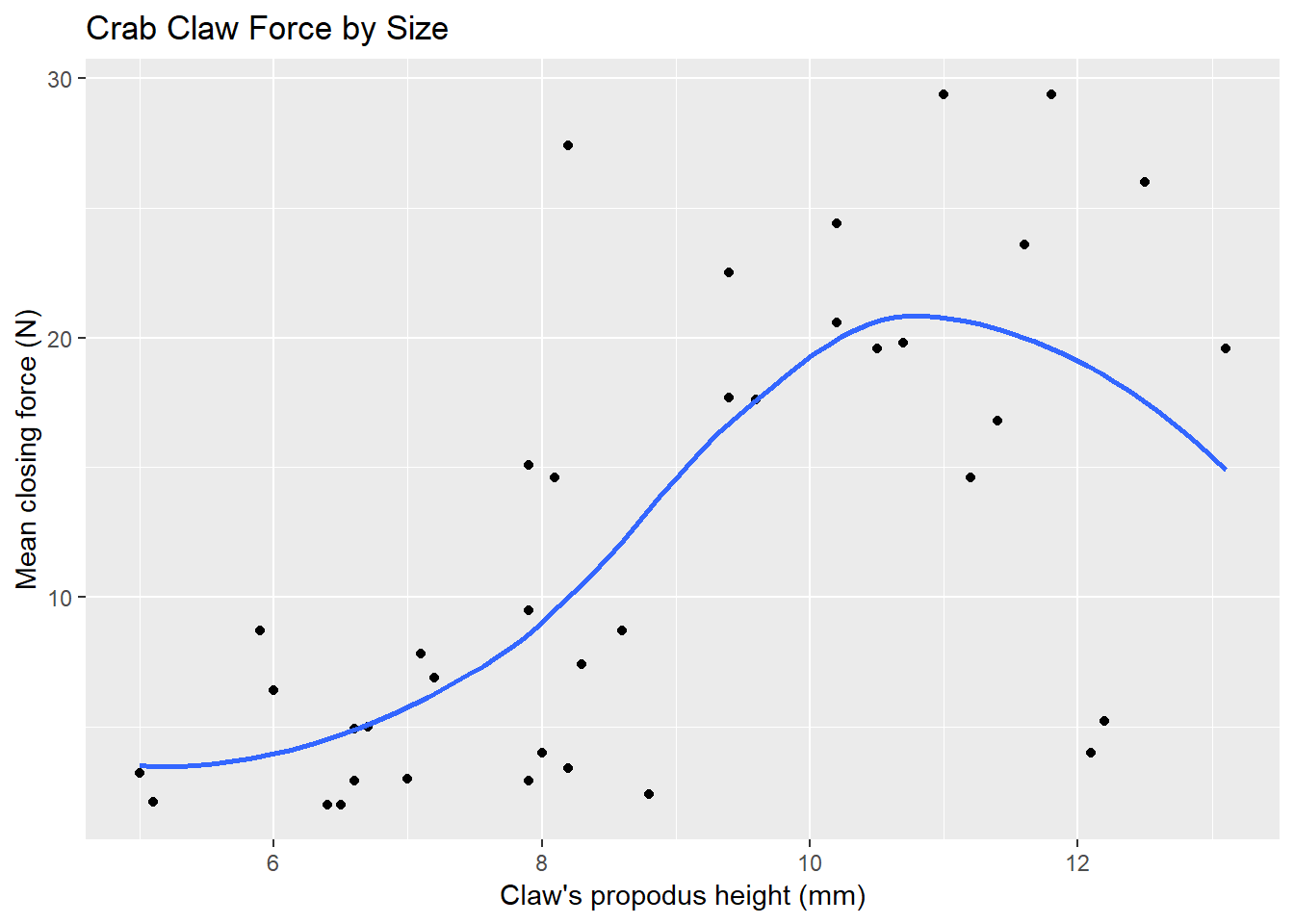
A loess smooth is a method of fitting a local polynomial regression model that R uses as its generic smooth for scatterplots with fewer than 1000 observations. Think of the loess as a way of fitting a curve to data by tracking (at point x) the points within a neighborhood of point x, with more emphasis given to points near x. It can be adjusted by tweaking two specific parameters, in particular:
- a
spanparameter (defaults to 0.75) which is also called \(\alpha\) in the literature, that controls the degree of smoothing (essentially, how larger the neighborhood should be), and - a
degreeparameter (defaults to 2) which specifies the degree of polynomial to be used. Normally, this is either 1 or 2 - more complex functions are rarely needed for simple scatterplot smoothing.
In addition to the curve, smoothing procedures can also provide confidence intervals around their main fitted line. Consider the following plot, which adjusts the span and also adds in the confidence intervals.
ggplot(crabs, aes(x = height, y = force)) +
geom_point() +
geom_smooth(method = "loess", span = 0.5, se = TRUE) +
labs(title = "Crab Claw Force by Size",
x = "Claw's propodus height (mm)", y = "Mean closing force (N)")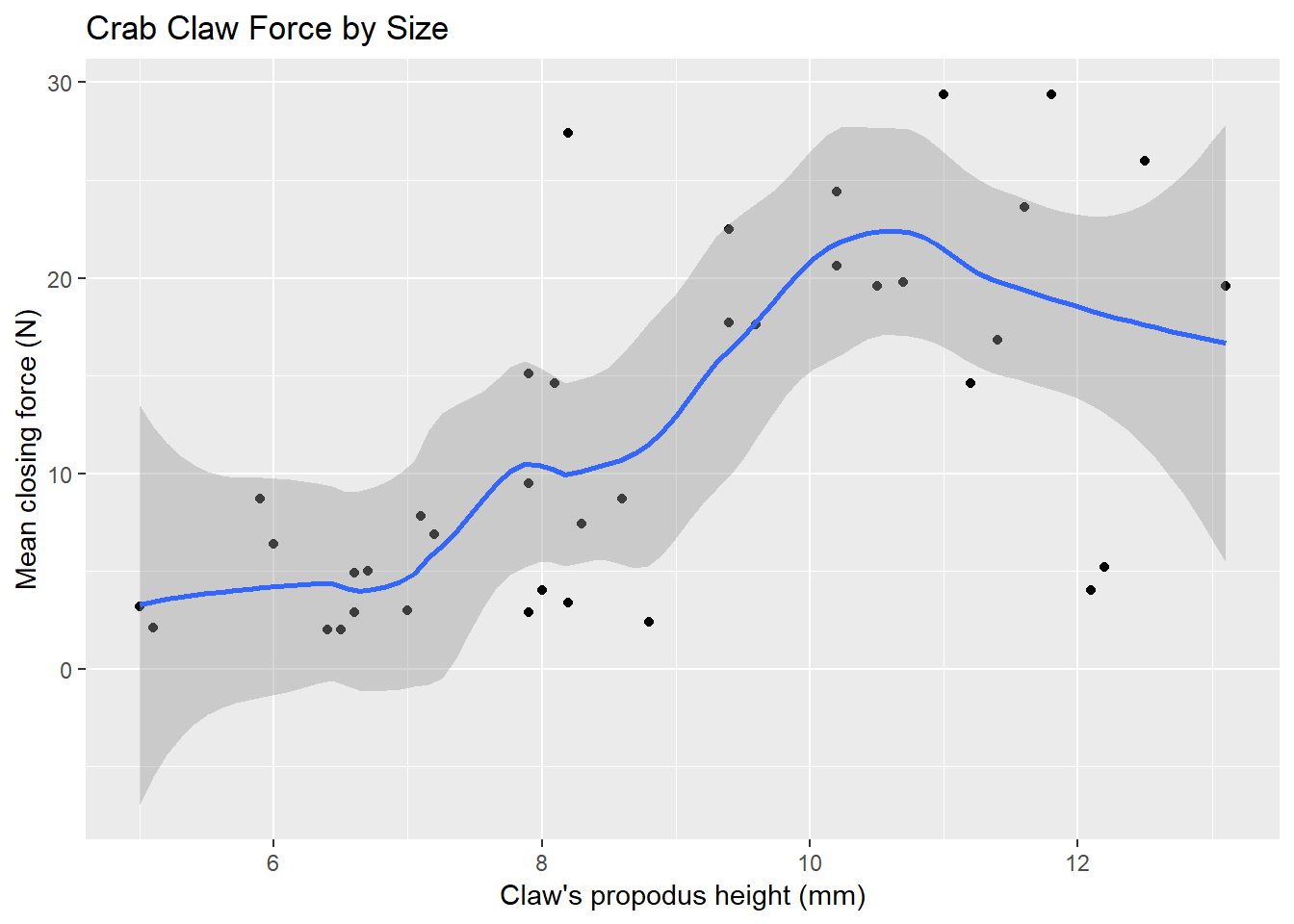
By reducing the size of the span, our resulting picture shows a much less smooth function that we generated previously.
12.2.1 Smoothing within Species
We can, of course, produce the plot above with separate smooths for each of the three species of crab.
ggplot(crabs, aes(x = height, y = force, group = species, color = species)) +
geom_point(size = 3) +
geom_smooth(method = "loess", se = FALSE) +
labs(title = "Crab Claw Force by Size",
x = "Claw's propodus height (mm)", y = "Mean closing force (N)")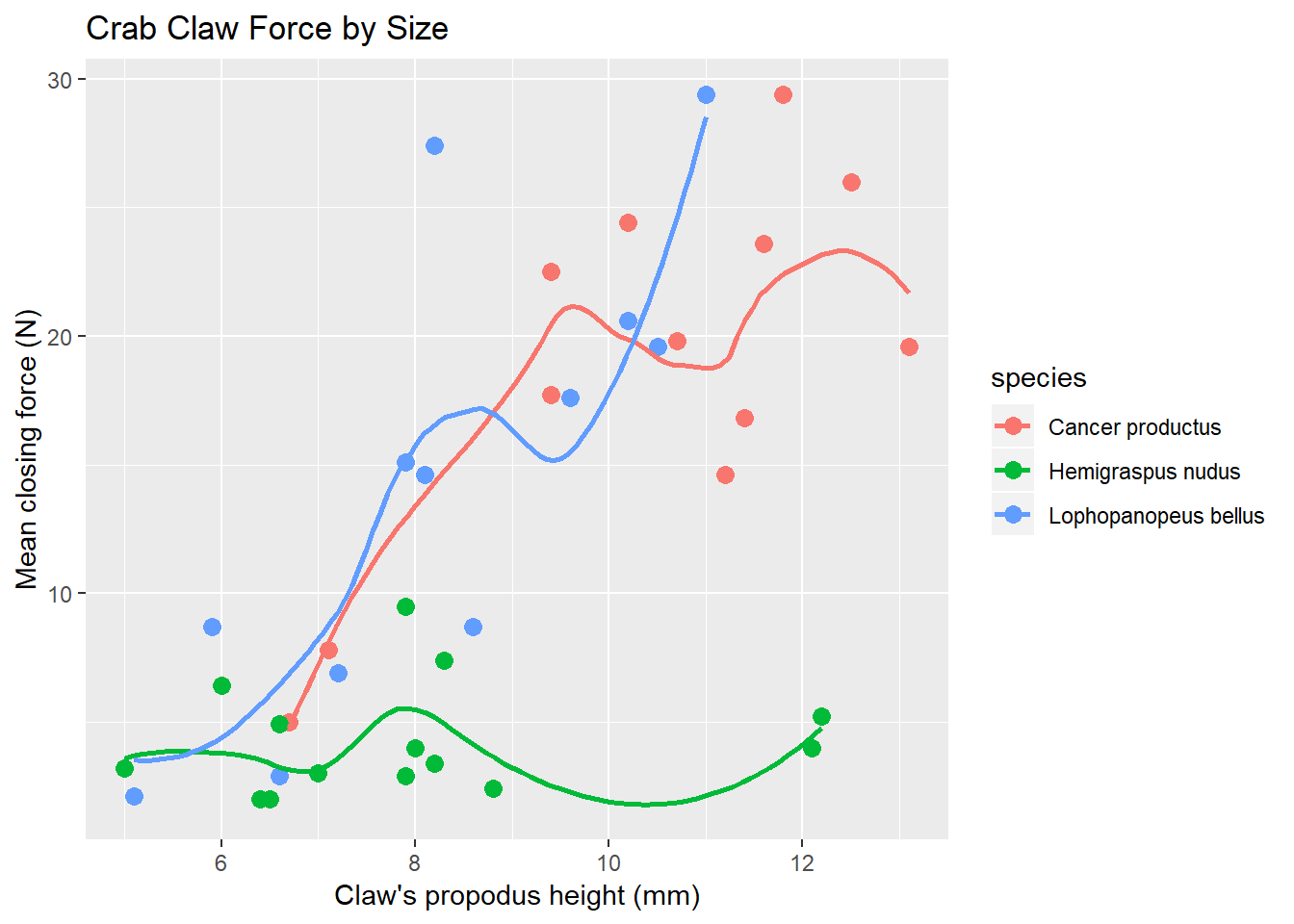
If we want to add in the confidence intervals (here I’ll show them at 90% rather than the default of 95%) then this plot should be faceted. Note that by default, what is displayed when se = TRUE are 95% prediction intervals - the level function in stat_smooth [which can be used in place of geom_smooth] is used here to change the coverage percentage from 95% to 90%.
ggplot(crabs, aes(x = height, y = force, group = species, color = species)) +
geom_point() +
stat_smooth(method = "loess", level = 0.90, se = TRUE) +
guides(color = FALSE) +
labs(title = "Crab Claw Force by Size",
caption = "with loess smooths and 90% confidence intervals",
x = "Claw's propodus height (mm)", y = "Mean closing force (N)") +
facet_wrap(~ species)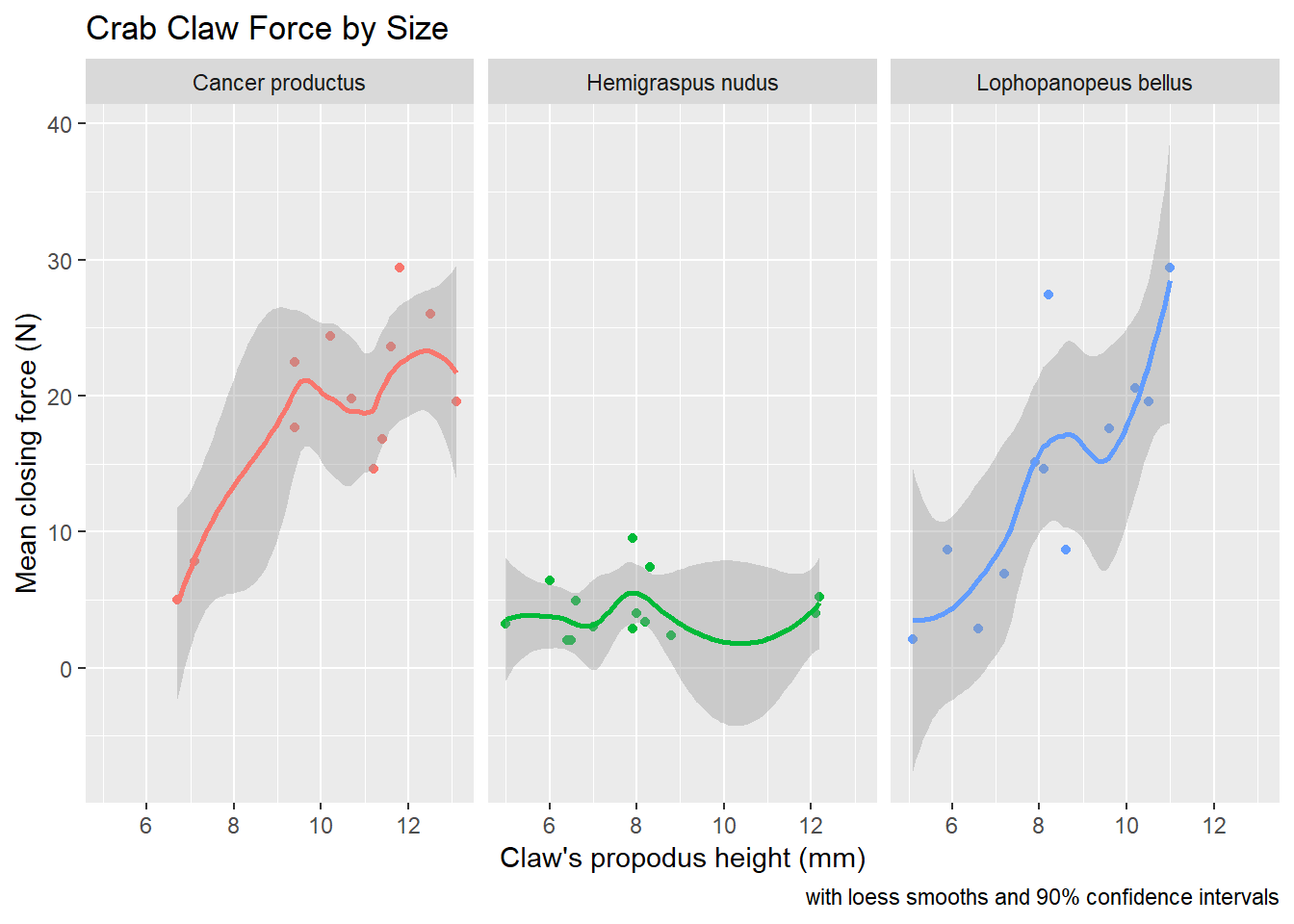
More on these and other confidence intervals later, especially in part B.
12.3 Fitting a Linear Regression Model
Suppose we plan to use a simple (least squares) linear regression model to describe force as a function of height. Is a least squares model likely to be an effective choice here?
The plot below shows the regression line predicting closing force as a function of propodus height. Here we annotate the plot to show the actual fitted regression line, which required fitting it with the lm statement prior to developing the graph.
mod <- lm(force ~ height, data = crabs)
ggplot(crabs, aes(x = height, y = force)) +
geom_point() +
geom_smooth(method = "lm", color = "red") +
labs(title = "Crab Claw Force by Size with Linear Regression Model",
x = "Claw's propodus height (mm)", y = "Mean closing force (N)") +
annotate("text", x = 11, y = 0, color = "red", fontface = "italic",
label = paste( "Force - ", signif(coef(mod)[1],3), " + ",
signif(coef(mod)[2],3), " Height" ))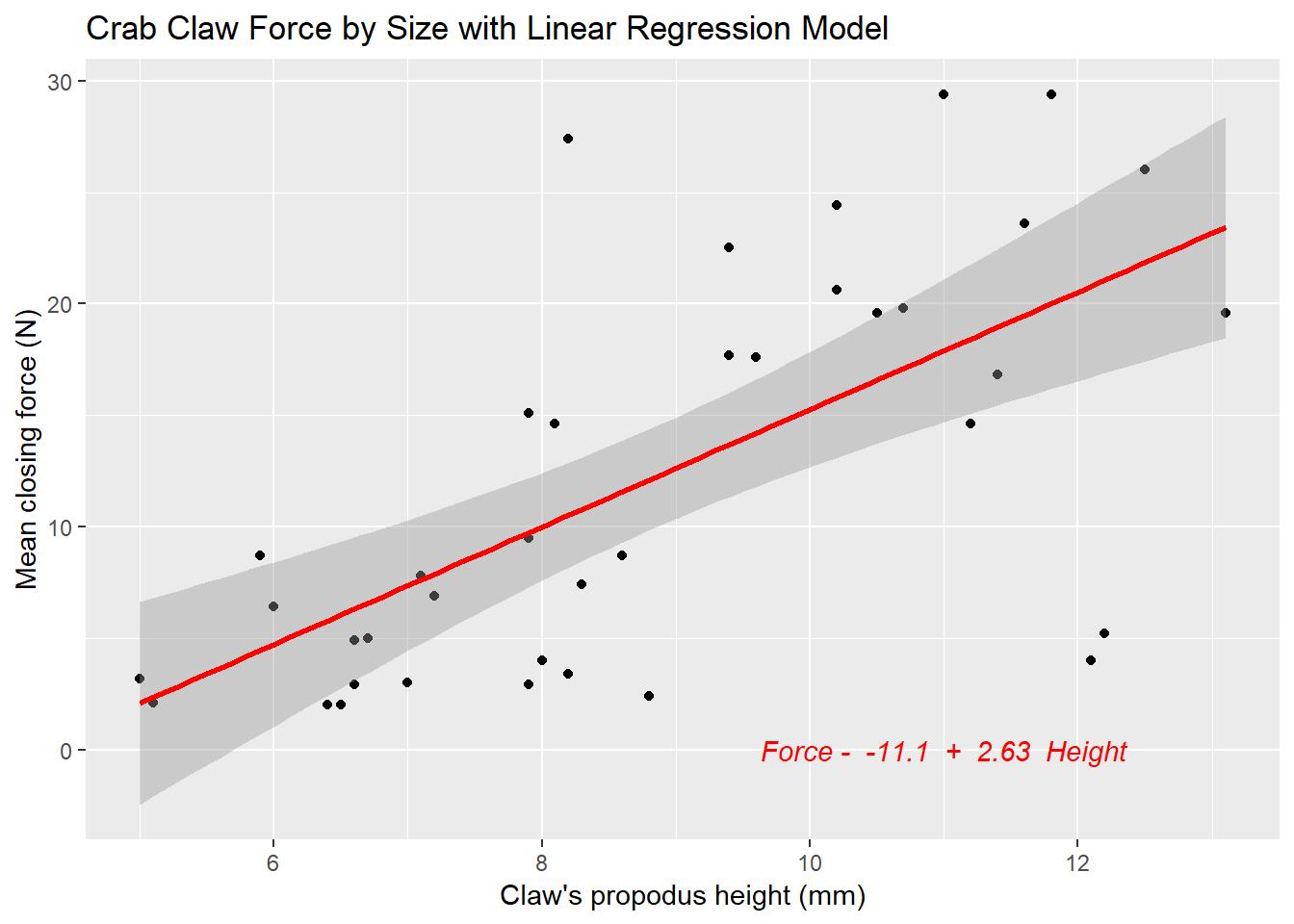
The lm function, again, specifies the linear model we fit to predict force using height. Here’s the summary.
Call:
lm(formula = force ~ height, data = crabs)
Residuals:
Min 1Q Median 3Q Max
-16.794 -3.811 -0.239 4.144 16.881
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -11.087 4.622 -2.40 0.022 *
height 2.635 0.509 5.18 8.7e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.89 on 36 degrees of freedom
Multiple R-squared: 0.427, Adjusted R-squared: 0.411
F-statistic: 26.8 on 1 and 36 DF, p-value: 8.73e-06Again, the key things to realize are:
- The outcome variable in this model is force, and the predictor variable is height.
- The straight line model for these data fitted by least squares is force = -11.1 + 2.63 height.
- The slope of height is positive, which indicates that as height increases, we expect that force will also increase. Specifically, we expect that for every additional mm of height, the force will increase by 2.63 Newtons.
- The multiple R-squared (squared correlation coefficient) is 0.427, which implies that 42.7% of the variation in force is explained using this linear model with height. It also implies that the Pearson correlation between force and height is the square root of 0.427, or 0.653.
12.4 Is a Linear Model Appropriate?
The zoology (at least as described in Ramsey and Schafer (2002)) suggests that the actual nature of the relationship would be represented by a log-log relationship, where the log of force is predicted by the log of height.
This log-log model is an appropriate model when we think that percentage increases in X (height, here) lead to constant percentage increases in Y (here, force).
To see the log-log model in action, we plot the log of force against the log of height. We could use either base 10 (log10 in R) or natural (log in R) logarithms.
ggplot(crabs, aes(x = log(height), y = log(force))) +
geom_point() +
geom_smooth(method = "lm") +
labs(title = "Log-Log Model for Crabs data")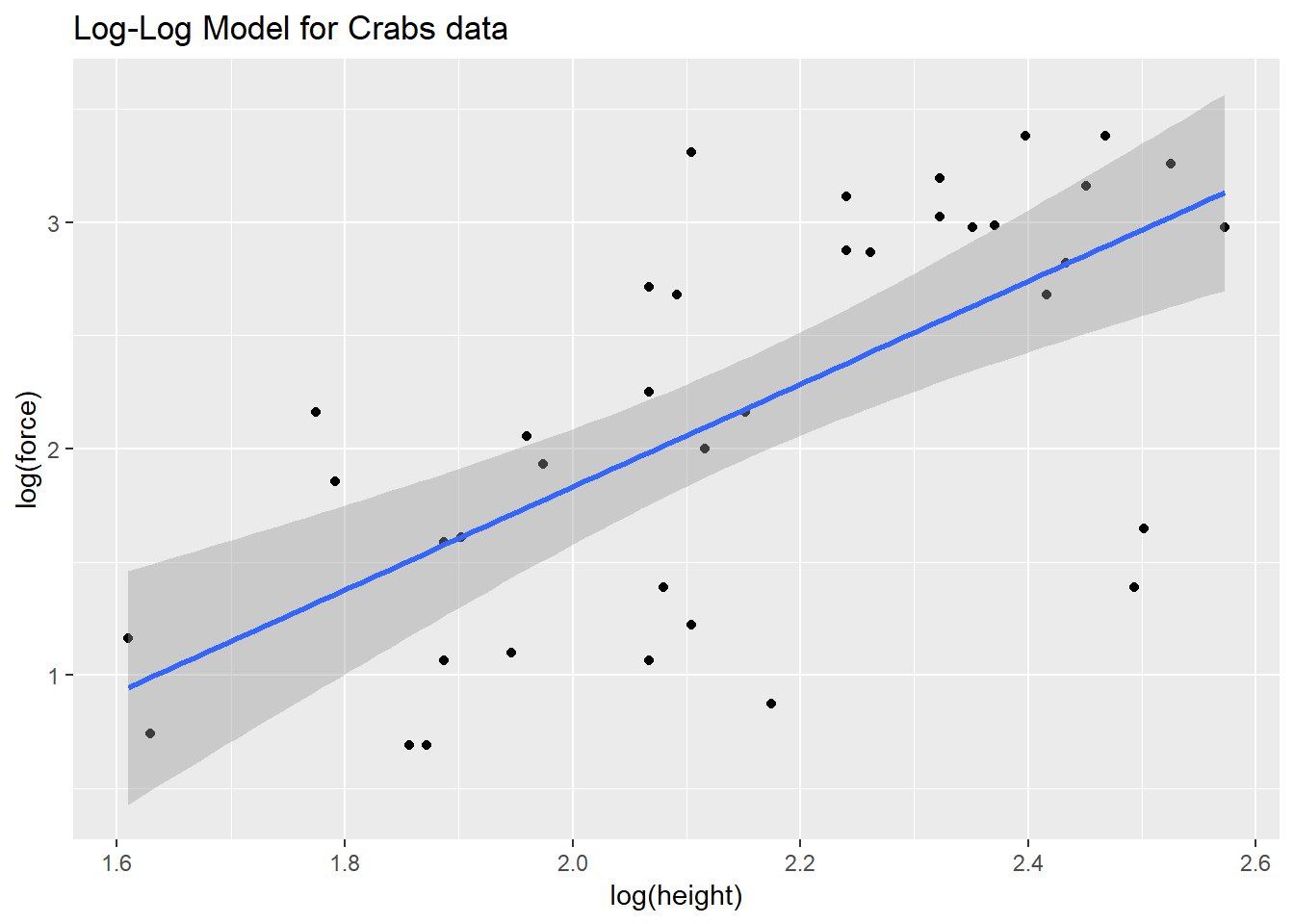
The correlations between the raw force and height and between their logarithms turn out to be quite similar, and because the log transformation is monotone in these data, there’s actually no change at all in the Spearman correlations.
| Correlation of | Pearson r | Spearman r |
|---|---|---|
| force and height | 0.653 | 0.657 |
| log(force) and log(height) | 0.662 | 0.657 |
12.4.1 The log-log model
Call:
lm(formula = log(force) ~ log(height), data = crabs)
Residuals:
Min 1Q Median 3Q Max
-1.566 -0.445 0.188 0.480 1.242
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.710 0.925 -2.93 0.0059 **
log(height) 2.271 0.428 5.30 6e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.675 on 36 degrees of freedom
Multiple R-squared: 0.438, Adjusted R-squared: 0.423
F-statistic: 28.1 on 1 and 36 DF, p-value: 5.96e-06Our regression equation is log(force) = -2.71 + 2.27 log(height).
So, for example, if we found a crab with propodus height = 10 mm, our prediction for that crab’s claw force (in Newtons) based on this log-log model would be…
- log(force) = -2.71 + 2.27 log(10)
- log(force) = -2.71 + 2.27 x 2.303
- log(force) = 2.519
- and so predicted force = exp(2.519) = 12.417 Newtons, which, naturally, we would round to 12.4 Newtons to match the data set’s level of precision.
12.4.2 How does this compare to our original linear model?
Call:
lm(formula = force ~ height, data = crabs)
Residuals:
Min 1Q Median 3Q Max
-16.794 -3.811 -0.239 4.144 16.881
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -11.087 4.622 -2.40 0.022 *
height 2.635 0.509 5.18 8.7e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.89 on 36 degrees of freedom
Multiple R-squared: 0.427, Adjusted R-squared: 0.411
F-statistic: 26.8 on 1 and 36 DF, p-value: 8.73e-06The linear regression equation is force = -11.1 + 2.63 height.
So, for example, if we found a crab with propodus height = 10 mm, our prediction for that crab’s claw force (in Newtons) based on this linear model would be…
- force = -11.087 + 2.635 x 10
- force = -11.087 + 26.348
- so predicted force = 15.261, which we would round to 15.3 Newtons.
So, it looks like the two models give meaningfully different predictions.
12.5 Making Predictions with a Model
A simpler way to get predictions for a new value like height = 10 mm from our models is available.
fit lwr upr
1 15.3 1.05 29.5We’d interpret this result as saying that the linear model’s predicted force associated with a single new crab claw with propodus height 10 mm is 15.3 Newtons, and that a 95% prediction interval for the true value of such a force for such a claw is between 1.0 and 29.5 Newtons. More on prediction intervals later.
12.5.1 Predictions After a Transformation
We can also get predictions from the log-log model.
fit lwr upr
1 2.52 1.13 3.91Of course, this prediction is of the log(force) for such a crab claw. To get the prediction in terms of simple force, we’d need to back out of the logarithm, by exponentiating our point estimate and the prediction interval endpoints.
fit lwr upr
1 12.4 3.08 50We’d interpret this result as saying that the log-log model’s predicted force associated with a single new crab claw with propodus height 10 mm is 12.4 Newtons, and that a 95% prediction interval for the true value of such a force for such a claw is between 3.1 and 50.0 Newtons.
12.5.2 Comparing Model Predictions
Suppose we wish to build a plot of force vs height with a straight line for the linear model’s predictions, and a new curve for the log-log model’s predictions, so that we can compare and contrast the implications of the two models on a common scale. The predict function, when not given a new data frame, will use the existing predictor values that are in our crabs data. Such predictions are often called fitted values.
To put the two sets of predictions on the same scale despite the differing outcomes in the two models, we’ll exponentiate the results of the log-log model, and build a little data frame containing the heights and the predicted forces from that model.
Now, we’re ready to use the geom_smooth approach to plot the linear fit, and geom_line (which also fits curves) to display the log-log fit.
ggplot(crabs, aes(x = height, y = force)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE, col="blue", linetype = 2) +
geom_line(data = loglogdat, col = "red", linetype = 2, size = 1) +
annotate("text", 7, 12, label = "Linear Model", col = "blue") +
annotate("text", 10, 8, label = "Log-Log Model", col = "red") +
labs(title = "Comparing the Linear and Log-Log Models for Crab Claw data")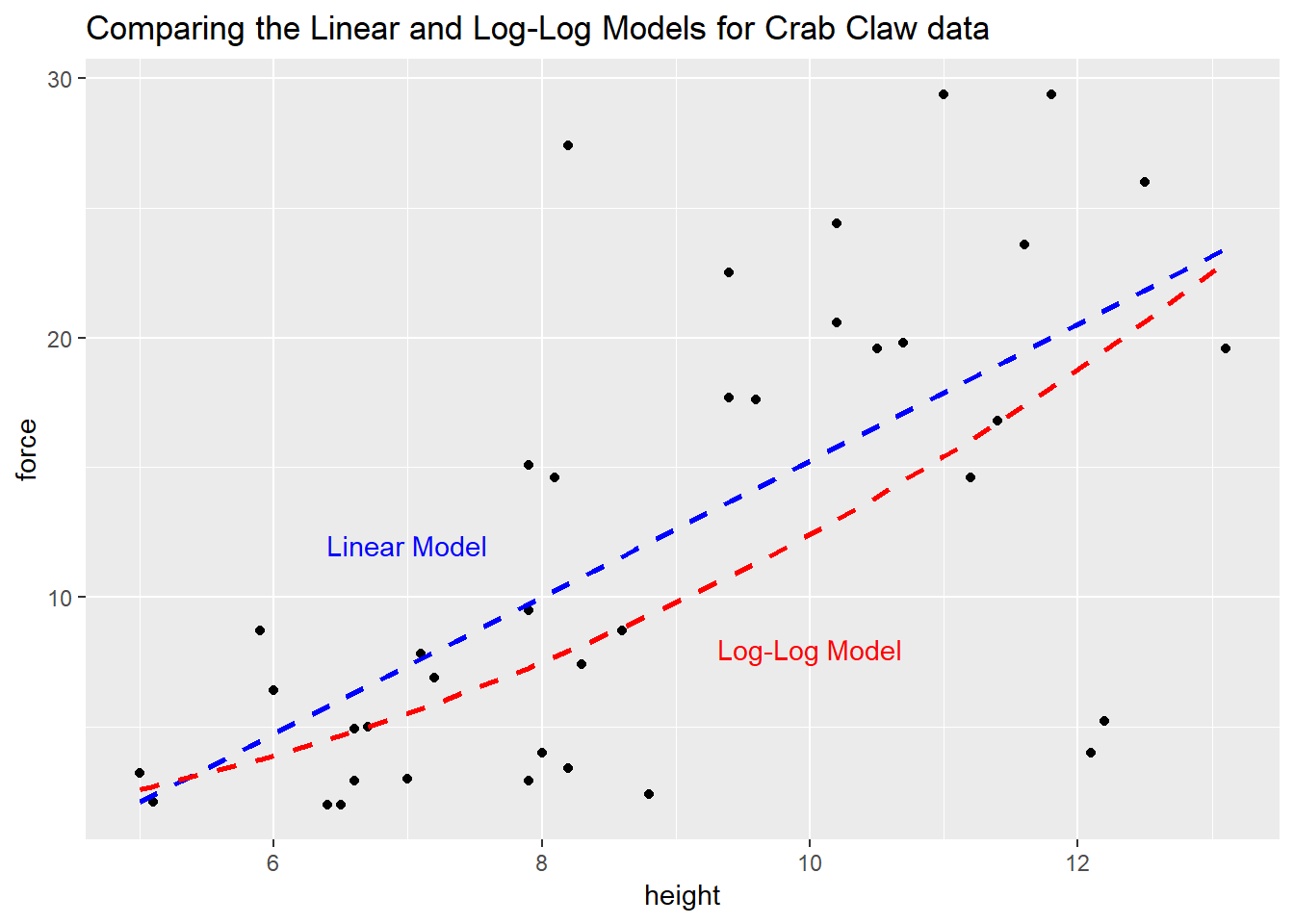
Based on these 38 crabs, we see some modest differences between the predictions of the two models, with the log-log model predicting generally lower closing force for a given propodus height than would be predicted by a linear model.
References
Ramsey, Fred L., and Daniel W. Schafer. 2002. The Statistical Sleuth: A Course in Methods of Data Analysis. Second. Pacific Grove, CA: Duxbury.
Yamada, SB, and EG Boulding. 1998. “Claw Morphology, Prey Size Selection and Foraging Efficiency in Generalist and Specialist Shell-Breaking Crabs.” Journal of Experimental Marine Biology and Ecology 220: 191–211. http://www.science.oregonstate.edu/~yamadas/SylviaCV/BehrensYamada_Boulding1998.pdf.